TEXTO - Unidade dos Sistemas de multimédia
Foi iniciado o estudo de uma subunidade dentro da unidade de multimédia dedicada ao texto. Este é o meio dominante para a apresentação de informação baseada em computador. Este pode ser criado de duas maneiras: a partir de editores de texto para produzir plain text (texto não formatado) - ex: Bloco de Notas; a partir de processadores de texto, originando rich text (conteúdos formatados) - ex: Microsoft Word. O texto é a forma mais comum de divulgar informação nos mais variados meios, incluindo revistas, jornais, SMS, livros e email.
Padrões de Codificação de Caracteres
Uma codificação de caracteres é um padrão que relaciona um determinado conjunto de caracteres com um conjunto de outros modos de armazenar informação, como números ou pulsos elétricos. A codificação tem como objetivo facilitar o armazenamento e transmissão de texto em sistemas informáticos ou através de redes. Exemplos comuns são o código morse o ASCII e Unicode. Estes dois últimos serão explorados nos parágrafos seguintes.
ASCII
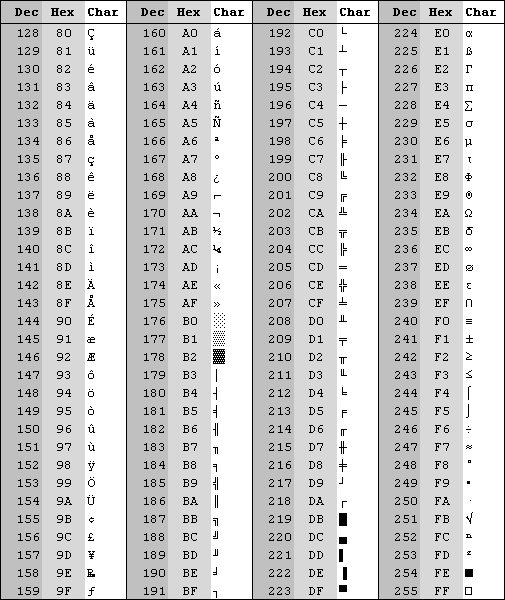 ASCII (American Standard Code for Information Interchange) designa uma tabela de código desenvolvida nos Estados Unidos da América na década de 60, dada a necessidade de criar um padrão que pudesse ser utilizado por todos os computadores, facilitando assim a comunicação entre eles e a troca de dados que esta implica.
ASCII (American Standard Code for Information Interchange) designa uma tabela de código desenvolvida nos Estados Unidos da América na década de 60, dada a necessidade de criar um padrão que pudesse ser utilizado por todos os computadores, facilitando assim a comunicação entre eles e a troca de dados que esta implica.A tabela ASCII utiliza conjuntos de 7 bits para representar 128 caracteres, muito deles adequados apenas à língua inglesa.
Apesar de ter sido uma enorme inovação e de grande parte das codificações de caracteres atuais se terem desenvolvido a partir dele, este padrão de codificação apresenta grandes fragilidades ao mudar de linguagem como por exemplo na utilização do alfabeto árabe e consegue suportar apenas um número limitado de caracteres, 256.
Unicode
 O Unicode é hoje utilizado em sistemas operativos, e-mails, páginas web, fontes, entre outros.
O Unicode é hoje utilizado em sistemas operativos, e-mails, páginas web, fontes, entre outros.Este código foi desenvolvido por uma associação de empresas, de entre elas, a Apple, a Adobe, a Microsoft,
a HP e a IBM. Este código resolve muitos dos problemas do código ASCII pois define todos os caracteres da maior parte das
línguas do mundo.
O código (conjunto de códigos, pare ser mais preciso) permite representar
conjuntos até 4 bytes (32 bits) para codificar caracteres utilizados pelos
idiomas modernos e as formas clássicas de alguns idiomas.
Entre os caracteres suportados e codificados por este código estão, símbolos de pontuação, caracteres acentuados,
símbolos técnicos e matemáticos e símbolos gráficos denominados dingbats.
Sem comentários:
Enviar um comentário